학습 내용
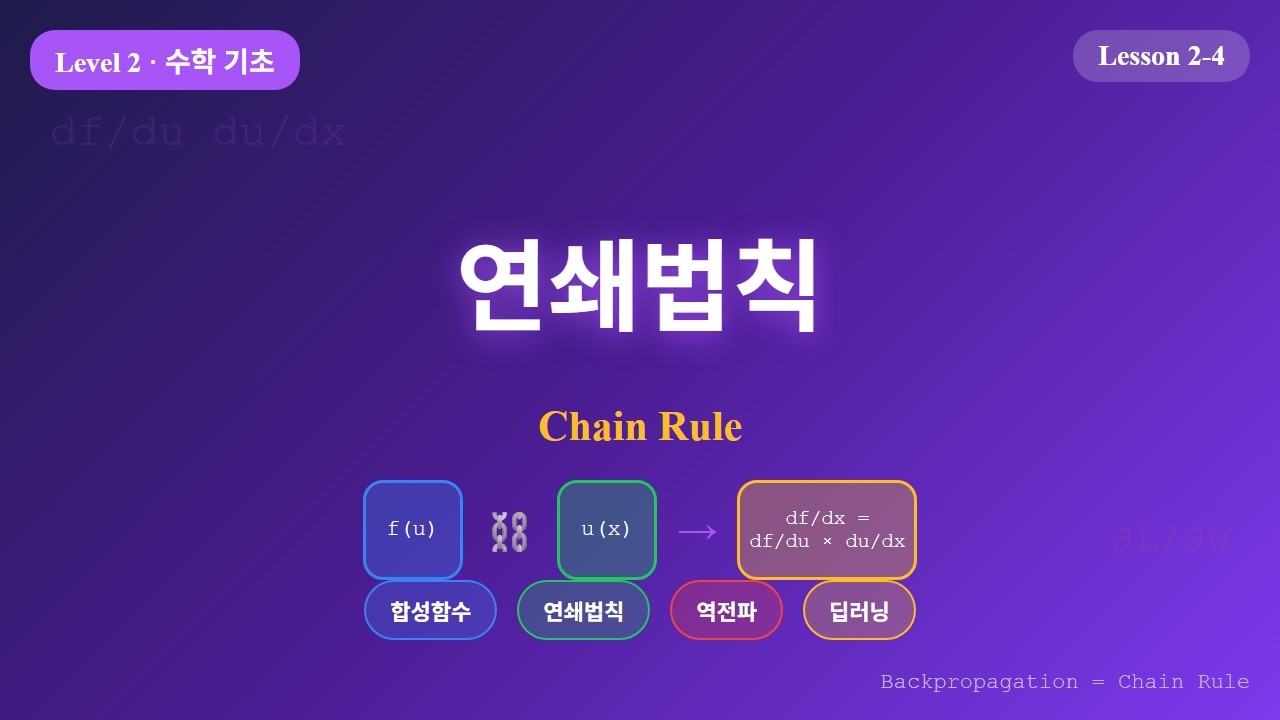
연쇄법칙 (Chain Rule)
학습 목표
이 레슨을 마치면 여러분은:
- •합성함수가 무엇인지 일상적인 비유로 이해합니다
- •연쇄법칙 공식 df/dx = df/du * du/dx 를 적용할 수 있습니다
- •Python으로 연쇄법칙을 수치적으로 검증할 수 있습니다
- •순전파와 역전파의 차이를 설명할 수 있습니다
- •역전파(backpropagation)가 연쇄법칙의 반복 적용임을 이해합니다
"연쇄법칙은 도미노 효과와 같습니다. 앞의 변화가 뒤로 전달되고, 뒤의 영향을 앞으로 되짚어 갈 수 있습니다."
1. 비유로 시작하기 -- 도미노 효과
연쇄법칙을 이해하려면 도미노를 떠올려 보세요.
도미노 A를 밀면 B가 넘어지고, B가 넘어지면 C가 넘어집니다. A가 C에 미치는 영향은?
A → B → C
(C가 B에 반응하는 정도) × (B가 A에 반응하는 정도) = C가 A에 반응하는 정도!
이것이 바로 연쇄법칙입니다. 중간 단계를 거치더라도, 각 단계의 변화율을 곱하면 전체 변화율을 알 수 있습니다.
또 다른 비유: 환율 변환을 생각해 보세요.
| 단계 | 변환 | 비율 |
|---|---|---|
| 원화 -> 달러 | 1000원 = 1달러 | du/dx = 1/1000 |
| 달러 -> 유로 | 1달러 = 0.9유로 | df/du = 0.9 |
| 원화 -> 유로 | 직접 계산 | df/dx = 0.9/1000 = du/dx * df/du |
2. 합성함수란?
합성함수는 함수 안에 함수가 들어있는 구조입니다.
예:
분해 함수 안쪽 함수 바깥 함수 x가 바뀌면 → u가 바뀌고 → f가 바뀐다
신경망이 바로 거대한 합성함수입니다!
| 구조 | 합성함수 관점 |
|---|---|
| 입력 x | 가장 안쪽 |
| 1층: h = W1*x + b1 | 첫 번째 함수 |
| 2층: y = W2*h + b2 | 두 번째 함수 |
| 손실: L = (y - target)^2 | 가장 바깥 함수 |
3. 연쇄법칙 공식
핵심 공식
전체 변화율 = (바깥 함수의 변화율) × (안쪽 함수의 변화율)
함수가 3개 이상 합성되어도 같은 원리입니다:
일 때:
각 단계의 변화율을 모두 곱하면 됩니다!
4. 단계별 계산 예시
예제 1:
| 단계 | 계산 |
|---|---|
| Step 1: 분해 | 안쪽: , 바깥: |
| Step 2: 각각 미분 | , |
| Step 3: 곱하기 | |
| 검증 | → ✓ |
예제 2:
| 단계 | 계산 |
|---|---|
| Step 1: 분해 | 안쪽: , 바깥: |
| Step 2: 각각 미분 | , |
| Step 3: 곱하기 | |
| 검증 | → ✓ |
5. Python으로 연쇄법칙 검증하기
수치 미분으로 우리가 손으로 계산한 결과를 확인해 봅시다.
실행해보기: 연쇄법칙 수치 검증
pythonimport numpy as np def numerical_derivative(f, x, h=1e-7): """수치 미분: f(x)의 도함수를 근사 계산""" return (f(x + h) - f(x - h)) / (2 * h) # === 예제 1: f(x) = (x + 2)^2 === print("=== Example 1: f(x) = (x + 2)^2 ===") print() def f1(x): return (x + 2)**2 def u1(x): return x + 2 def outer1(u): return u**2 x = 3.0 # 수치 미분으로 직접 계산 numerical = numerical_derivative(f1, x) # 연쇄법칙으로 계산: df/du * du/dx df_du = numerical_derivative(outer1, u1(x)) # 2u du_dx = numerical_derivative(u1, x) # 1 chain_rule = df_du * du_dx print(f"x = {x}") print(f" Direct numerical derivative: {numerical:.6f}") print(f" Chain rule: df/du * du/dx = {df_du:.4f} * {du_dx:.4f} = {chain_rule:.6f}") print(f" Analytical: 2(x+2) = {2*(x+2):.6f}") print() # === 예제 2: f(x) = (3x^2 + 1)^3 === print("=== Example 2: f(x) = (3x^2 + 1)^3 ===") print() def f2(x): return (3*x**2 + 1)**3 def u2(x): return 3*x**2 + 1 def outer2(u): return u**3 x = 1.0 numerical = numerical_derivative(f2, x) df_du = numerical_derivative(outer2, u2(x)) du_dx = numerical_derivative(u2, x) chain_rule = df_du * du_dx print(f"x = {x}") print(f" Direct numerical derivative: {numerical:.6f}") print(f" Chain rule: df/du * du/dx = {df_du:.4f} * {du_dx:.4f} = {chain_rule:.6f}") print(f" Analytical: 18x(3x^2+1)^2 = {18*x*(3*x**2+1)**2:.6f}") print() # === 3단계 합성: f(x) = sin(exp(x^2)) === print("=== Example 3: f(x) = sin(exp(x^2)) (triple composition) ===") print() def f3(x): return np.sin(np.exp(x**2)) x = 0.5 numerical = numerical_derivative(f3, x) # 분해: v = x^2, u = exp(v), f = sin(u) v = x**2 u = np.exp(v) df_du = np.cos(u) # d(sin(u))/du = cos(u) du_dv = np.exp(v) # d(exp(v))/dv = exp(v) dv_dx = 2*x # d(x^2)/dx = 2x chain_rule = df_du * du_dv * dv_dx print(f"x = {x}") print(f" Direct numerical: {numerical:.6f}") print(f" Chain rule (3 steps): {chain_rule:.6f}") print(f" Match: {abs(numerical - chain_rule) < 1e-5}")
세 가지 예제 모두에서 연쇄법칙 결과와 직접 수치 미분 결과가 일치합니다!
6. 순전파 vs 역전파
신경망에서 연쇄법칙이 어떻게 쓰이는지 이해하려면 순전파와 역전파를 구분해야 합니다.
| 구분 | 순전파 (Forward Pass) | 역전파 (Backward Pass) |
|---|---|---|
| 방향 | 입력 -> 출력 | 출력 -> 입력 |
| 목적 | 예측값 계산 | 그래디언트 계산 |
| 수학 | 합성함수 계산 | 연쇄법칙 적용 |
| 비유 | 도미노 넘어뜨리기 | 어떤 도미노가 원인인지 역추적 |
text순전파: x --> h --> y --> L (데이터가 앞으로 흐름) 역전파: x <-- h <-- y <-- L (그래디언트가 뒤로 흐름) dL/dW1 dL/dh dL/dy dL/dL=1
7. Python으로 2층 신경망 순전파/역전파 구현
이제 가장 핵심적인 부분입니다. 순수 numpy만으로 2층 신경망의 순전파와 역전파를 직접 구현해 봅시다.
실행해보기: 2층 신경망 forward & backward
pythonimport numpy as np np.random.seed(42) # --- 네트워크 설정 --- # 입력: 2개, 은닉: 3개, 출력: 1개 input_size = 2 hidden_size = 3 output_size = 1 # 가중치 초기화 (작은 랜덤값) W1 = np.random.randn(input_size, hidden_size) * 0.5 # (2, 3) b1 = np.zeros((1, hidden_size)) # (1, 3) W2 = np.random.randn(hidden_size, output_size) * 0.5 # (3, 1) b2 = np.zeros((1, output_size)) # (1, 1) # ReLU 활성화 함수 def relu(x): return np.maximum(0, x) def relu_derivative(x): return (x > 0).astype(float) # 데이터 (1개 샘플) x = np.array([[1.0, 2.0]]) # 입력 (1, 2) target = np.array([[1.0]]) # 목표값 # ========== 순전파 (Forward Pass) ========== print("=" * 50) print("FORWARD PASS") print("=" * 50) # 1층: z1 = x @ W1 + b1, h = relu(z1) z1 = x @ W1 + b1 h = relu(z1) print(f"Input x: {x}") print(f"z1 = x @ W1 + b1: {z1}") print(f"h = relu(z1): {h}") # 2층: z2 = h @ W2 + b2 (출력층, 활성화 없음) z2 = h @ W2 + b2 y_pred = z2 print(f"y_pred = h @ W2 + b2: {y_pred}") # 손실: MSE = (y_pred - target)^2 loss = (y_pred - target) ** 2 print(f"Loss = (y_pred - target)^2 = {loss[0][0]:.6f}") # ========== 역전파 (Backward Pass) -- 연쇄법칙! ========== print() print("=" * 50) print("BACKWARD PASS (Chain Rule!)") print("=" * 50) # dL/dy_pred = 2 * (y_pred - target) dL_dy = 2 * (y_pred - target) print(f"Step 1: dL/dy_pred = 2*(y_pred - target) = {dL_dy}") # dL/dW2 = h^T @ dL_dy (chain rule: dL/dW2 = dL/dy * dy/dW2) dL_dW2 = h.T @ dL_dy dL_db2 = dL_dy print(f"Step 2: dL/dW2 = h^T @ dL_dy =") print(f" {dL_dW2}") # dL/dh = dL_dy @ W2^T (chain rule continues backward) dL_dh = dL_dy @ W2.T print(f"Step 3: dL/dh = dL_dy @ W2^T = {dL_dh}") # dL/dz1 = dL/dh * relu_derivative(z1) dL_dz1 = dL_dh * relu_derivative(z1) print(f"Step 4: dL/dz1 = dL/dh * relu_deriv(z1) = {dL_dz1}") # dL/dW1 = x^T @ dL_dz1 dL_dW1 = x.T @ dL_dz1 dL_db1 = dL_dz1 print(f"Step 5: dL/dW1 = x^T @ dL_dz1 =") print(f" {dL_dW1}") # ========== 경사하강법 업데이트 ========== print() print("=" * 50) print("GRADIENT DESCENT UPDATE") print("=" * 50) lr = 0.01 W2_new = W2 - lr * dL_dW2 b2_new = b2 - lr * dL_db2 W1_new = W1 - lr * dL_dW1 b1_new = b1 - lr * dL_db1 # 업데이트 후 순전파로 새 손실 확인 z1_new = x @ W1_new + b1_new h_new = relu(z1_new) y_new = h_new @ W2_new + b2_new loss_new = (y_new - target) ** 2 print(f"Learning rate: {lr}") print(f"Loss before: {loss[0][0]:.6f}") print(f"Loss after: {loss_new[0][0]:.6f}") if loss[0][0] > 0: pct = (loss[0][0] - loss_new[0][0]) / loss[0][0] * 100 print(f"Loss decreased by {pct:.2f}%!")
이 코드가 바로 딥러닝 프레임워크(PyTorch, TensorFlow)가 내부적으로 하는 일입니다! loss.backward() 한 줄이 위의 역전파 과정 전체를 자동으로 수행합니다.
8. 왜 역전파가 효율적인가?
연쇄법칙을 뒤에서 앞으로 적용하는 것이 핵심입니다.
text만약 순서대로 (앞에서 뒤로) 계산하면: dL/dW1을 구하려면 -> 처음부터 다시 계산 dL/dW2를 구하려면 -> 또 처음부터 다시 계산 = 중복 계산이 엄청나게 많음! 역전파 (뒤에서 앞으로): dL/dy를 한번 구하면 -> dL/dW2 계산에 재사용 -> dL/dh 계산에도 재사용 -> dL/dW1 계산에도 재사용 = 중복 계산 없이 효율적!
| 방식 | 계산량 | 비유 |
|---|---|---|
| 각각 따로 계산 | O(N^2) | 매번 처음부터 다시 추적 |
| 역전파 | O(N) | 한번 쭉 역추적하면 모두 해결 |
9. 연쇄법칙 시각화
연쇄법칙이 작동하는 모습을 그래프로 확인해 봅시다.
실행해보기: 합성함수와 연쇄법칙 시각화
pythonimport numpy as np import matplotlib.pyplot as plt # f(x) = (x + 2)^2 def f(x): return (x + 2)**2 def f_derivative(x): return 2 * (x + 2) # chain rule result x = np.linspace(-6, 4, 200) fig, axes = plt.subplots(1, 2, figsize=(14, 5)) # 왼쪽: 함수와 접선 ax1 = axes[0] ax1.plot(x, f(x), 'b-', linewidth=2, label='f(x) = (x+2)^2') # 몇 개 점에서 접선 표시 for x0 in [-4, -2, 0, 2]: slope = f_derivative(x0) y0 = f(x0) tangent = slope * (x - x0) + y0 ax1.plot(x, tangent, '--', alpha=0.5, label=f'x={x0}, slope={slope}') ax1.plot(x0, y0, 'ro', markersize=8) ax1.set_xlim(-6, 4) ax1.set_ylim(-5, 30) ax1.set_xlabel('x', fontsize=12) ax1.set_ylabel('f(x)', fontsize=12) ax1.set_title('f(x) = (x+2)^2 with tangent lines', fontsize=13) ax1.legend(fontsize=9) ax1.grid(True, alpha=0.3) # 오른쪽: 도함수 (연쇄법칙 결과) ax2 = axes[1] ax2.plot(x, f_derivative(x), 'r-', linewidth=2, label="f'(x) = 2(x+2)") ax2.axhline(y=0, color='black', linewidth=0.5) ax2.axvline(x=-2, color='gray', linestyle=':', alpha=0.5, label='minimum at x=-2') for x0 in [-4, -2, 0, 2]: slope = f_derivative(x0) ax2.plot(x0, slope, 'ro', markersize=8) ax2.annotate(f'slope={slope}', xy=(x0, slope), xytext=(x0+0.3, slope+1), fontsize=9) ax2.set_xlim(-6, 4) ax2.set_xlabel('x', fontsize=12) ax2.set_ylabel("f'(x)", fontsize=12) ax2.set_title("Derivative by chain rule: f'(x) = 2(x+2)", fontsize=13) ax2.legend(fontsize=10) ax2.grid(True, alpha=0.3) plt.tight_layout() plt.savefig('chain_rule_visual.png', dpi=80, bbox_inches='tight') plt.show() print("Left: The function and tangent lines at various points") print("Right: The derivative computed by chain rule") print("At x=-2, derivative=0 -> this is the minimum!")
10. 미분 3총사 완성!
지금까지 배운 세 가지 미분 개념이 신경망 학습의 수학적 기초를 이룹니다:
| 레슨 | 개념 | 핵심 아이디어 | 신경망에서의 역할 |
|---|---|---|---|
| 2-2 미분 | 변화율 계산 | 기울기 = 변화의 속도 | 손실이 얼마나 빨리 변하나 |
| 2-3 편미분 | 여러 변수 각각 미분 | 한 변수만 보고 나머지 고정 | 각 가중치의 영향력 측정 |
| 2-4 연쇄법칙 | 합성함수 미분 | 단계별 변화율을 곱함 | 역전파로 효율적 학습 |
핵심 요약
| 개념 | 설명 | 비유 |
|---|---|---|
| 합성함수 | 함수 안에 함수 | 도미노 체인 / 다층 신경망 |
| 연쇄법칙 | df/dx = df/du * du/dx | 환율 변환을 단계별로 곱하기 |
| 순전파 | 입력에서 출력으로 계산 | 도미노 넘어뜨리기 |
| 역전파 | 출력에서 입력으로 그래디언트 전파 | 원인을 역추적하기 |
| 효율성 | 중간 결과 재사용 | 한번 역추적으로 모든 가중치 업데이트 |
학습 체크리스트
- • 합성함수가 "함수 안의 함수"임을 안다
- • 연쇄법칙 공식 df/dx = df/du * du/dx 를 적용할 수 있다
- • Python으로 연쇄법칙을 수치적으로 검증할 수 있다
- • 순전파는 예측, 역전파는 학습이라는 것을 안다
- • 역전파가 연쇄법칙을 뒤에서 앞으로 적용하는 것임을 이해한다
- • 역전파가 효율적인 이유(중간 결과 재사용)를 설명할 수 있다
다음 강의 예고
"벡터와 행렬 기초" AI 연산의 95%는 행렬 곱셈! GPU와 HBM이 왜 중요한지 알아봅니다.
레슨 정보
- 레벨
- Level 2: 수학 기초
- 예상 소요 시간
- 3분 50초
- 참고 영상
- YouTube 링크
💡실습 환경 안내
코드 블록의 ▶ 실행 버튼을 누르면 브라우저에서 바로 Python을 실행할 수 있습니다.
별도 설치 없이 NumPy, Matplotlib 등 기본 라이브러리를 사용할 수 있습니다.